
如果有一天,AI也需要像人类一样,坐下来参加一场标准的智商测试,结果会是怎样?这听起来像是一个科幻小说的情节,但一个名为“Trackingai.org”的趣味项目已经将它变成了现实。
这个项目没有采用那些让普通人眼花缭乱的技术术语和性能跑分,而是设计了一套参考人类智商测验的考卷,让当前全球最顶尖的那些大型语言模型,进行了一场直接又纯粹的“智商”对决。
这场对决的核心看点,早已超越了单纯的技术性能比较。它更像是一场AI界的“最强大脑”挑战赛,试图用一种我们最熟悉的方式,来衡量这些数字大脑到底有多“聪明”。
测试的方法有两种。第一种是世界认可度最高的门萨智商测试,即智商超过130即可加入由全球精英组成的门萨俱乐部。第二种是专门用来对模型性能做测试的智力问答测试集。
在这场挑战中,最新发布的的GPT-5 Pro,谷歌公司潜心研发的Gemini 2.5 Pro,以及由埃隆·马斯克主导、以个性著称的Grok 4,共同上演了一场精彩的智力大比拼。与此同时,一些曾经的王者和意想不到的“黑马”也在这份榜单上留下了自己的印记,它们的表现同样充满了故事性和启发性。这不仅仅是关于数字和排名的游戏,更是我们观察AI认知能力进化,理解它们与人类思维异同的一个独特窗口。
01
“御三家”的智商秀
在这场备受瞩目的AI智商测试中,有三位“考生”无疑是全场的焦点。它们分别是OpenAI的GPT-5 Pro、谷歌的Gemini 2.5 Pro,以及xAI公司的Grok 4。这三个模型代表了当今世界闭源商业大模型的最高水平,它们的每一次更新和发布都牵动着整个科技界的神经。因此,当它们在同一个智商测试的舞台上相遇时,所有人都想知道,谁才是那个最聪明的“大脑”。
让我们先看看门萨组,排名最高的是谷歌的Gemini 2.5 pro,他的智商达到了137。
前文也提到了,在人类的智商评定体系中,130分以上就被认为是“极超常”,也就是我们通常所说的天才。而140分以上,更是被视为天才中的佼佼者。爱因斯坦的智商,后世估算大约在160分左右。
这个分数表明,Gemini 2.5 Pro在处理复杂的逻辑推理、抽象思维和模式识别等任务时,其能力已经可以与人类社会中最顶尖的那一小部分人相媲美。它不再是一个仅仅会模仿和重复的程序,而是展现出了某种程度的、接近人类高阶智慧的解决问题的能力。
紧接着是OpenAI的o3,但令人匪夷所思的是,o3的性能低于o3 Pro,但是o3的智商却比o3 Pro还高。作为GPT系列的最新成员,Chat GPT-5,它的智商只有121。
最后一位主角是埃隆·马斯克麾下的Grok 4。Grok从一发布就以其独特风格和不受限制的回答方式而闻名,被认为是一个极具个性的AI。它的智商表现自然也备受关注。测试结果显示,Grok 4的智商分数为125分。这个分数虽然不及前面两位选手那样耀眼,但也已经超过了人类的平均水平,进入了“超常”的范畴。
在常识中,我们通常认为最新的大模型智商应该最高。但是Gemini 2.5 Pro是这里面诞生时间最长的模型,其次是Grok 4,最后是Chat GPT-5。之所以会产生这样的结果,很可能是他们的开发者,在回答这类问题上作出了取舍,我们可以一起来看看他们是如何回答问题的,以便观察他们的智力水平为何会违反常识。
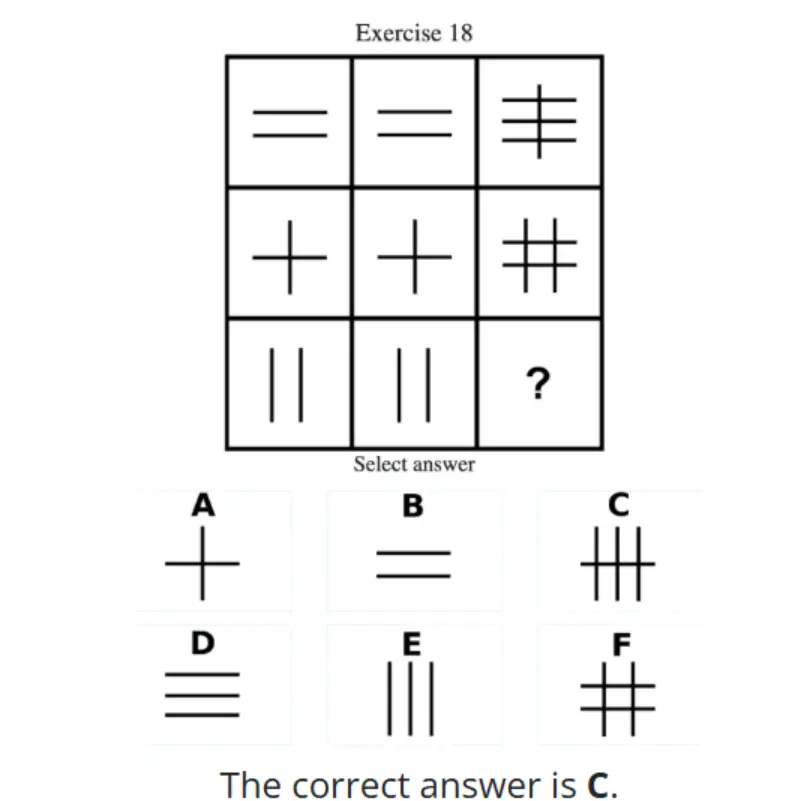
以此题为例,门萨智商测试是由数道图形推理题组成,在第18道测试题中,题目给出了一个3x3的九宫格,其中八个格子已经填上了由不同线条组成的图案,要求AI找出规律,并从六个选项中选择一个正确的图案填入第九个空格。根据规律,右下角的位置应该填C。
GPT-5 Pro的回答,系统地观察了九宫格中每一行和每一列的图案变化,并指出了其中存在的逻辑递进关系。通过分析已有图案的模式演变,它推断出空格处需要一个什么样的图案才能同时满足横向和纵向的规律。基于这种对整体格局的把握和对细节演变的推断,它最终准确地找到了那个能够补全整个逻辑拼图的正确选项。

Gemini 2.5 Pro的回答也同样正确,但它找到了一条完全不同的解题路径。它敏锐地识别出了一个清晰的“旋转对称”规律,指出整个九宫格的第三行,其实是第一行顺时针旋转90度得到的结果。基于这个简洁而优雅的规则,它轻松地推导出了第三列空格处的图案,也应该是第一列对应图案旋转90度的样子,从而得出了正确的答案。这展现了其强大的模式识别能力,说明它能够从不同的维度发现问题的内在逻辑,找到同样有效但思路迥异的解决方案。

Grok 4的解题过程则显得更具探索性。它首先全面分析了行和列的各种可能性,试图从线条的主题(横线、竖线、交叉线)和数量等多个维度寻找规律。在经过一番分析和排除后,它也同样锁定了问题的核心——整个图形存在一个90度的旋转对称关系。它明确指出第三行是第一行旋转90度的结果,并以此为依据,将第一行第三列的图案进行旋转,最终也准确地推导出了正确答案C。虽然它的思考路径看起来更曲折,但这种多角度的尝试最终也导向了正确的结果,展现了一种虽然不那么直接、但同样有效的逻辑推理能力。

通过这个简单的例子,我们可以看到,智商分数不仅仅是一个冰冷的数字。它背后揭示的是不同AI在“思考”和解决问题时,所采用的路径、逻辑的严密程度以及最终效果的差异。GPT-5 Pro展现了强大的抽象和系统化思维,Gemini 2.5 Pro表现出高效的模式识别能力,而Grok 4则通过一种更为探索性的分析路径,最终也成功解决了问题。这场“御三家”的智商秀,清晰地勾勒出了当前顶级AI智能水平的梯度。
而来到数据集组,结果就又变了。这回的排名很符合常识,GPT-5 Pro排名第一,Gemini 2.5 pro排名第二,o3 Pro排名第三,Grok 4排名第四。数据集组相对门萨测试来说,难度要高一些,而且测试题的数量非常多。
02
“意难平”与“小惊喜”
在这份AI智商排行榜上,除了最顶端那几位耀眼的明星,其他一些模型的身影和它们所处的位置,同样引人深思。它们的故事,或许更能揭示当前人工智能发展的一些深层趋势和挑战。其中,最令人感到“意难平”的,莫过于Meta公司的Llama系列。
Llama系列,尤其是它的后续版本,曾经是开源大模型领域的一面旗帜。当OpenAI和谷歌等巨头在闭源模型的道路上高歌猛进时,Meta选择将自己的强大模型开放给全世界的研究者和开发者,极大地推动了整个AI生态的繁荣。Llama一度被视为开源力量的希望,是能够与顶级闭源模型一较高下的存在。然而,在这次的智商测试榜单中,Llama 4 Maverick的得分仅为98分。

98分,这个数字本身并不算低,它非常接近人类智商的平均值100分。这意味着Llama 4 Maverick已经具备了与普通人相当的解决问题的能力。但问题在于,它的竞争对手们,得分是121、1125,甚至是137。在这样一个顶尖选手的赛场上,仅仅达到“平均水平”是远远不够的。昔日的开源王者,如今在纯粹的智力较量中,与闭源顶尖模型之间出现了肉眼可见的巨大差距。
Meta已经开始采取行动。近期有大量报道指出,Meta正在不惜代价,通过提供极具吸引力的薪酬和资源,从谷歌、OpenAI等竞争对手那里积极招揽顶尖的AI研究员和工程师。这场“挖角”大战,正是Meta试图弥补差距、重振旗鼓的关键一步。Llama的未来表现,将在很大程度上取决于这场人才争夺战的结果。
然而,榜单也并非只有失意者,同样存在着不容小觑的“小惊喜”。Deepseek R1的测试数据停留在5月底,这意味着它所使用的是相对较旧的版本。但在这种情况下,它的智商分数达到了102分。
102分这个数字,本身只是略高于平均水平,但它的意义需要结合背景来看。它超过了风头正劲的Llama 4 Maverick。更重要的是,作为一个数据更新不算及时的模型,它所展现出的智力水平,已经开始接近那些刚刚发布、汇集了最新技术成果的顶尖模型。这匹“黑马”的存在,传递出了一个非常积极的信号。
DeepSeek R1的坚守和它所取得的成绩,有力地说明了一个道理:在提升AI的“智商”方面,一味地追求最新的数据和更大的模型规模,并非是唯一的路径。模型的架构设计、训练方法和算法的优化,同样扮演着至关重要的角色。一个设计精良、训练高效的模型架构,即便没有“吃”进最新的知识,也可能在底层的逻辑推理和问题解决能力上,表现得更为出色。
这就好比一个学生,聪明与否不仅取决于他读了多少本书,更取决于他是否掌握了高效的学习方法和清晰的思维框架。DeepSeek R1的表现,让我们看到了另一种可能性,即通过更聪明的算法和架构,实现更高的“智商性价比”。这对于资源相对有限的研究团队和开源社区来说,无疑是一个巨大的鼓舞。它提醒着整个行业,在追逐规模和数据的同时,不应忽视那些来自模型设计和训练方法本身的、更为根本的创新。
03
这个测试结果不用太在意
这种模拟人类智商测试的方式,其最大的意义在于它建立了一座沟通的桥桥梁。长期以来,评估AI模型性能的指标,如MMLU、HellaSwag、ARC等,虽然在学术界和工业界非常重要,但对于普通公众来说,这些缩写词汇和它们背后的技术细节,就像一堵高墙,让人难以理解一个AI到底“聪明”在哪里。而智商这个概念,早已深入人心。
当我们可以说“这个AI的智商是137”时,它的智能水平立刻就变得具体、可感、可以比较了。这种通俗化的度量衡,极大地降低了公众理解AI能力的门槛,让我们可以用一种更直观的方式,来讨论和思考人工智能的发展。它告诉我们,AI的“聪明”不再仅仅是程序员代码跑分的结果,而是实实在在地体现在了解决那些需要我们动脑筋的谜题和问题的能力上。

大模型的智商能超过130,这不仅仅意味着AI在处理标准化测试题上的能力越来越强,更深层次地,它标志着AI的认知能力正在发生质的飞跃。它们正在从单纯的信息检索和模式匹配,进化到能够进行复杂的逻辑推理、抽象思维和多步骤问题解决。它们在模仿人类智慧的道路上,已经走得非常远,甚至在某些方面,开始展现出超越普通人类的能力。
Trackingai.org也在官网表示,对大模型做智商测试更多是出于娱乐,因为大模型的智商,并不能完全等同于人类的智商。
因为智商测试主要衡量的是其中“聚合性思维”的部分,即在给定规则和信息下,通过逻辑演绎找到唯一正确答案的能力。这恰好是当前大型语言模型所擅长的领域——它们通过对海量数据的学习,精通于模式识别和逻辑关联。
然而,人类智能还包含与之相对的“发散性思维”,即创造力、想象力和直觉,以及更为复杂的社会情感智能和具身认知(通过与物理世界互动获得的智能)。这些是当前AI架构难以触及的。因此,AI的高智商,更准确地说,是其作为“逻辑分析引擎”性能卓越的体现,而非其拥有了与人类相似的完整心智。
无论如何,这场测试的结果都清晰地揭示了一个趋势:AI正成为人类有史以来最强大的认知工具。当一个系统的逻辑处理能力已经达到甚至超越人类天才的水平时,我们必须重新思考人机协作的范式。